Форматирование и отладка кода
Написание кода — безусловно, важнейшая задача при изучении любого языка программирования. Однако не менее важно понимать, какие возможности предоставляет экосистема языка для поддержки, сопровождения и развития этого кода.
Хороший код должен быть чистым, читаемым и эффективным. Это не только облегчает работу над проектом в будущем, но и делает ваш код понятным для других разработчиков. Даже самый аккуратный код иногда может содержать ошибки или работать не так, как ожидается — в таких случаях крайне важно иметь в распоряжении удобные инструменты для отладки и профилирования, которые помогут быстро найти и устранить проблему.
В этой главе мы подробно рассмотрим инструменты, которые помогают писать, анализировать и отлаживать код, включая средства автоматического форматирования, линтеры, профайлеры и отладчики. Эти инструменты являются неотъемлемой частью современного процесса разработки и позволяют сосредоточиться на логике и качестве программ.
Форматирование кода
Ещё 10 лет назад, когда появлялся новый язык программирования, сразу же начинались споры о том, как правильно форматировать код: где должна находиться открывающая скобка, использовать ли пробелы или табуляцию, и другие подобные вопросы. Эти обсуждения часто отнимали много времени и сил, особенно на этапе командной работы и ревью кода.
Однако с появлением языка Go ситуация изменилась. Его авторы приняли важное решение — включить в стандартный инструментарий утилиту автоматического форматирования кода (gofmt). Эта утилита приводила исходный код к единому стилю, определённому разработчиками языка. Благодаря этому подходу вопрос форматирования был фактически снят с повестки: разработчики больше не тратили время на споры, а сосредоточились на логике и архитектуре программ.
С тех пор такая практика получила широкое распространение. Сегодня многие языки программирования поставляются со встроенными средствами форматирования кода или поддерживают их через официальные инструменты. Это помогает разработчикам:
- соблюдать единый стиль кодовой базы
- повышать читаемость кода
- избегать ненужных обсуждений во время ревью кода
Автоматическое форматирование стало важной частью современного процесса разработки, упрощая командную работу и делая проекты более поддерживаемыми.
Язык Zig не стал исключением — он также поставляется с утилитой автоматического форматирования кода (zig fmt), которая приводит код к стилю, определённому авторами языка. Это помогает разработчикам соблюдать единые стандарты оформления и значительно улучшает читаемость кода.
Давайте рассмотрим как использовать zig fmt. Предположим, у вас есть файл main.zig с неотформатированным кодом:
const std= @import("std");
pub fn main() void
{
std.debug.print("Hello, world!\n", .{});
}
Выполнив команду:
zig fmt main.zig
Код будет автоматически приведён к стандартному стилю:
const std = @import("std");
pub fn main() void {
std.debug.print("Hello, world!\n", .{});
}
Как правило, вам почти никогда не придётся запускать команду форматирования вручную — большинство современных текстовых редакторов и интегрированных сред разработки (IDE) автоматически форматируют код при сохранении файла. Это помогает поддерживать единый стиль оформления и значительно упрощает процесс разработки.
Однако форматирование кода — это лишь один из способов повышения читаемости и качества программ. В арсенале любого разработчика, помимо форматтера, обычно есть линтер — а иногда и целый набор линтеров.
Линтеры анализируют исходный код и выявляют потенциальные ошибки, нарушения соглашений по стилю и другие проблемы, которые могут привести к некорректному или непредсказуемому поведению программы. Они могут, например:
- проверять, что имена переменных и функций соответствуют принятым правилам;
- следить за тем, чтобы комментарии были оформлены правильно;
- указывать на использование устаревших или опасных конструкций;
- рекомендовать более надёжные или читаемые альтернативы;
Кроме того, линтеры играют важную роль в дисциплине программирования: они помогают разработчику не только избегать ошибок, но и писать более чистый, структурированный и поддерживаемый код. По сути, линтер — это цифровой напарник, который подсказывает, где и как можно улучшить ваш код.
К сожалению, во многих языках линтеры не входят в стандартную поставку и обычно разрабатываются сторонними энтузиастами или сообществом — часто с некоторым опозданием по отношению к развитию самого языка. Zig не стал исключением: поскольку это довольно молодой язык, его линтер также находится на ранней стадии развития.
Тем не менее, линтер для Zig уже существует и умеет выполнять базовые проверки на соответствие стилю и потенциальные ошибки. С течением времени можно ожидать, что его функциональность будет расширяться: появятся новые правила, улучшится качество анализа и удобство использования.
Рекомендуется включить линтер в свой рабочий процесс уже сейчас, чтобы с самого начала привыкать к более строгим и качественным подходам к написанию кода. Мы будем использовать линтер, доступный по адресу https://github.com/DonIsaac/zlint. Для того чтобы установить линтер на ваш компьютер, выполните следующие команды в терминале:
curl -fsSL https://raw.githubusercontent.com/DonIsaac/zlint/refs/heads/main/tasks/install.sh | bash
Чтобы сконфигурировать линтер, необходимо создать файл zlint.json в корневой папке проекта. Этот файл будет содержать настройки линтера — такие как правила проверки, уровни серьёзности предупреждений и другие параметры. Для проверки кода достаточно выполнить команду zlint в директории проекта. Линтер проанализирует код и выведет рекомендации по его улучшению.
Вот пример вывода линтера:
$ zlint
⚠ suppressed-errors: Caught error is mishandled with `unreachable`
╭─[build.zig:7:58]
6 │ fn create(b: *std.Build) *TracyStep {
7 │ const self = b.allocator.create(TracyStep) catch unreachable;
· ───────────
8 │ self.* = .{
╰────
help: Use `try` to propagate this error. If this branch shouldn't happen, use `@panic` or `std.debug.panic` instead.
⚠ suppressed-errors: `catch` statement suppresses errors
╭─[src/main.zig:242:60]
241 │ remainder.shrinkRetainingCapacity(0);
242 │ remainder.insertSlice(0, buf[ln + 1 .. n]) catch {};
· ────────
243 │ }
╰────
help: Handle this error or propagate it to the caller with `try`.
⚠ suppressed-errors: `catch` statement suppresses errors
╭─[src/main.zig:314:56]
313 │ if (Record.init(path_str, responseTime)) |record| {
314 │ threadMap.put(record.path, record) catch {};
· ────────
315 │ } else |_| {}
╰────
help: Handle this error or propagate it to the caller with `try`.
⚠ unsafe-undefined: `undefined` is missing a safety comment
╭─[src/main.zig:56:25]
55 │ // Global array of HashMaps for threads
56 │ var threadMaps: []Map = undefined;
· ─────────
╰────
help: Add a `SAFETY: <reason>` before this line explaining why this code is safe.
⚠ unsafe-undefined: `undefined` is missing a safety comment
╭─[src/main.zig:96:33]
96 │ var pool: std.Thread.Pool = undefined;
· ─────────
97 │ try pool.init(std.Thread.Pool.Options{ .allocator = allocator, .n_jobs = cpu_num });
╰────
help: Add a `SAFETY: <reason>` before this line explaining why this code is safe.
⚠ suppressed-errors: `catch` statement suppresses errors
╭─[src/root.zig:287:52]
286 │ // Pre-allocate a HashMap with reasonable capacity to reduce rehashing
287 │ threadMaps[threadId].ensureTotalCapacity(1024) catch {};
· ────────
╰────
help: Handle this error or propagate it to the caller with `try`.
⚠ unsafe-undefined: `undefined` is missing a safety comment
╭─[src/root.zig:36:25]
35 │ // Global array of HashMaps for threads
36 │ var threadMaps: []Map = undefined;
· ─────────
╰────
help: Add a `SAFETY: <reason>` before this line explaining why this code is safe.
⚠ unsafe-undefined: `undefined` is missing a safety comment
╭─[src/root.zig:109:33]
109 │ var pool: std.Thread.Pool = undefined;
· ─────────
110 │ try pool.init(std.Thread.Pool.Options{ .allocator = allocator, .n_jobs = cpu_num });
╰────
help: Add a `SAFETY: <reason>` before this line explaining why this code is safe.
Found 0 errors and 8 warnings across 3 files in 2ms.
Профилирование кода
Профилирование — это один из ключевых этапов оптимизации программ, который позволяет определить, какие части кода потребляют наибольшее количество ресурсов. Благодаря профилированию разработчик получает наглядные данные о реальном поведении программы, что помогает выявлять узкие места и принимать обоснованные решения по улучшению производительности. В этом разделе мы рассмотрим инструменты и методы профилирования в Zig. Основные задачи профиллирования:
- Оценка времени выполнения функций;
- Оценка использования памяти;
- Оценка частоты вызова отдельных блоков кода;
- Оценка загрузки CPU и GPU;
Существует много способов профиллирования вашей программы, но мы рассмотрим несколько подходов, которые автор использовал при написании программ. И начнем мы с того что дает нам язык из коробки, а дает он нам возможность использовать std.time.
Самый простой способ оценить время выполнения некоторых участков вашего кода это использовать оценку времени выполнения используя std.time. Давайте рассмотрим пример:
const std = @import("std");
pub fn main() !void {
var timer = try std.time.Timer.start();
// Код для профилирования
slowFunction();
const elapsed = timer.read();
std.debug.print("Время выполнения: {} нс\n", .{elapsed});
}
fn slowFunction() void {
var i: u64 = 0;
while (i < 1_000_000_000) : (i += 1) {}
}
Если запустить данный код, то мы увидим время выполнения функции slowFunction() в наносекундах:
$ zig build run
Время выполнения: 1276699417 нс
Второй способ оценить эффективность вашего кода это использовать такие утилиты как hyperfine (https://github.com/sharkdp/hyperfine) или poop (https://github.com/andrewrk/poop). Они позволяют оценить время выполнения вашей программы и сравнить разные варианты реализации между собой. Вторая утилита poop создана автором языка zig, но к сожалению она особо не развивается и не кросплатформенная, поэтому я приведу пример использования hyperfine. Предположим, что у нас есть программа с двумя алгоритмами, которые нам надо сравнить:
const std = @import("std");
pub fn main() !void {
const args = try std.process.argsAlloc(std.heap.page_allocator);
defer std.process.argsFree(std.heap.page_allocator, args);
if (std.mem.eql(u8, args[1], "1")) {
slowFunction1();
} else {
slowFunction2();
}
}
fn slowFunction1() void {
var i: u64 = 0;
while (i < 1_000_000_000) : (i += 1) {}
}
fn slowFunction2() void {
var i: u64 = 0;
while (i < 1_000_000_000) : (i += 2) {}
}
Чтобы сравнить два варианта, соберём нашу программу и запустим её с помощью hyperfine:
$ zig build
$ hyperfine "./zig-out/bin/time 1" "./zig-out/bin/time 2"
Benchmark 1: ./zig-out/bin/time 1
Time (mean ± σ): 1.262 s ± 0.011 s [User: 1.257 s, System: 0.003 s]
Range (min … max): 1.249 s … 1.277 s 10 runs
Benchmark 2: ./zig-out/bin/time 2
Time (mean ± σ): 629.0 ms ± 3.9 ms [User: 624.9 ms, System: 1.8 ms]
Range (min … max): 626.8 ms … 639.7 ms 10 runs
Summary
./zig-out/bin/time 2 ran
2.01 ± 0.02 times faster than ./zig-out/bin/time 1
Как мы видим, вторая реализация нашей функции работает в два раза быстрее первой — и это действительно так, ведь именно так мы и задумывали. Конечно, это довольно простой способ сравнения, но он не даёт нам понимания, где именно возникают проблемы в коде. Поэтому пойдём дальше и рассмотрим более сложные методы профилирования.
Опытные разработчики часто используют инструменты профилирования, такие как valgrind, perf (Linux), VTune (Windows) и DTrace (macOS), чтобы получить более детальную информацию о работе программы. Эти инструменты позволяют определить участки кода с наибольшей нагрузкой, частыми операциями выделения памяти и другими важными характеристиками. Это лишь наиболее популярные из доступных решений — существуют и другие утилиты для профилирования, например, Samply (https://github.com/mstange/samply).
Так как автор ведет разработку под Mac OS, то мы рассмотрим два инструмента - профилирование через Time Profiler, а также использование Samply для более глубокого анализа кода. Итак, давайте начнем с профилирования через Time Profiler. Предположим, что у нас есть программа, которая читает довольно большой файл (около 30Gb) и обрабатывает данные из него в 10 потоков - например, считает математические операции такие как максимальное значение, среднее значение и т.д. И нам необходимо понять, где мы тратим больше всего времени. Для этого мы запустим программу Instruments, выберем Time Profiler и запустим нашу программу через него. В результате мы получаем следующий вывод:
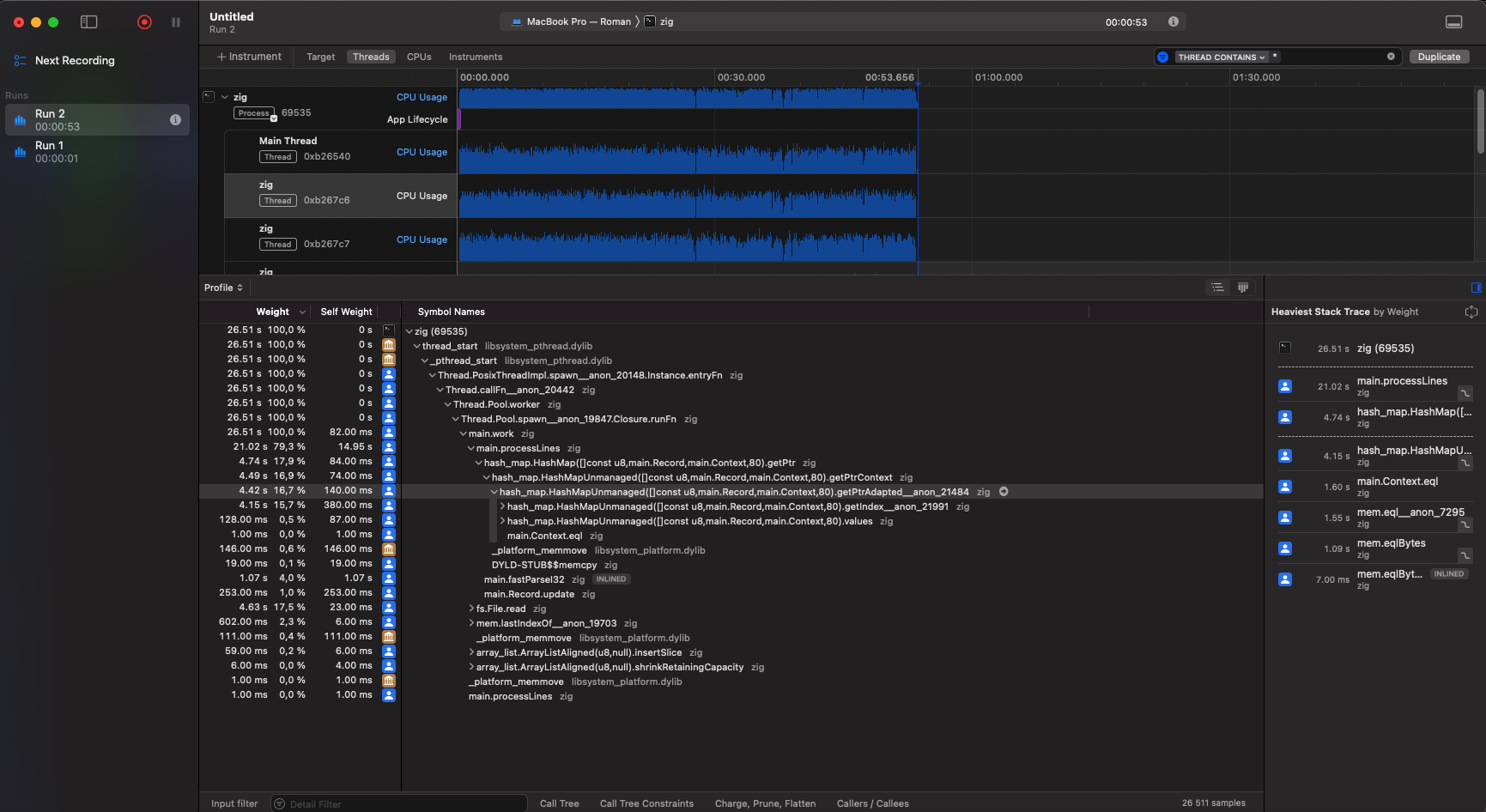
На полученном профиле мы видим активность выбранного потока: наибольшее время тратится на чтение файла и обновление структуры данных типа HashMap, предположительно в момент записи промежуточных результатов.
Что можно извлечь из этой информации?
Например, вместо того чтобы каждый поток читал файл самостоятельно, мы можем использовать механизм отображения файла в память (memory mapping) — это позволит потокам работать с общими данными, избегая лишнего I/O.
Для оптимизации работы с хеш-таблицей стоит рассмотреть альтернативные, более быстрые структуры данных или, как минимум, попробовать заменить используемый алгоритм хеширования на более производительный.
Если вы ведете разработку под Linux, то вы можете получить аналогичные результаты с помощью утилиты perf и утилиты hotspot (https://github.com/KDAB/hotspot), которая позволяет визуализировать результаты профилирования.
Теперь давайте рассмотрим как получить аналогичные результаты через утилиту samply. Для этого вам необходимо установить samply и запустить нашу программу:
samply record ./zig-out/bin/zig ../billion_logs.txt
В результате, вы получите информацию о времени выполнения вашей программы, включая информацию о времени выполнения каждого потока:
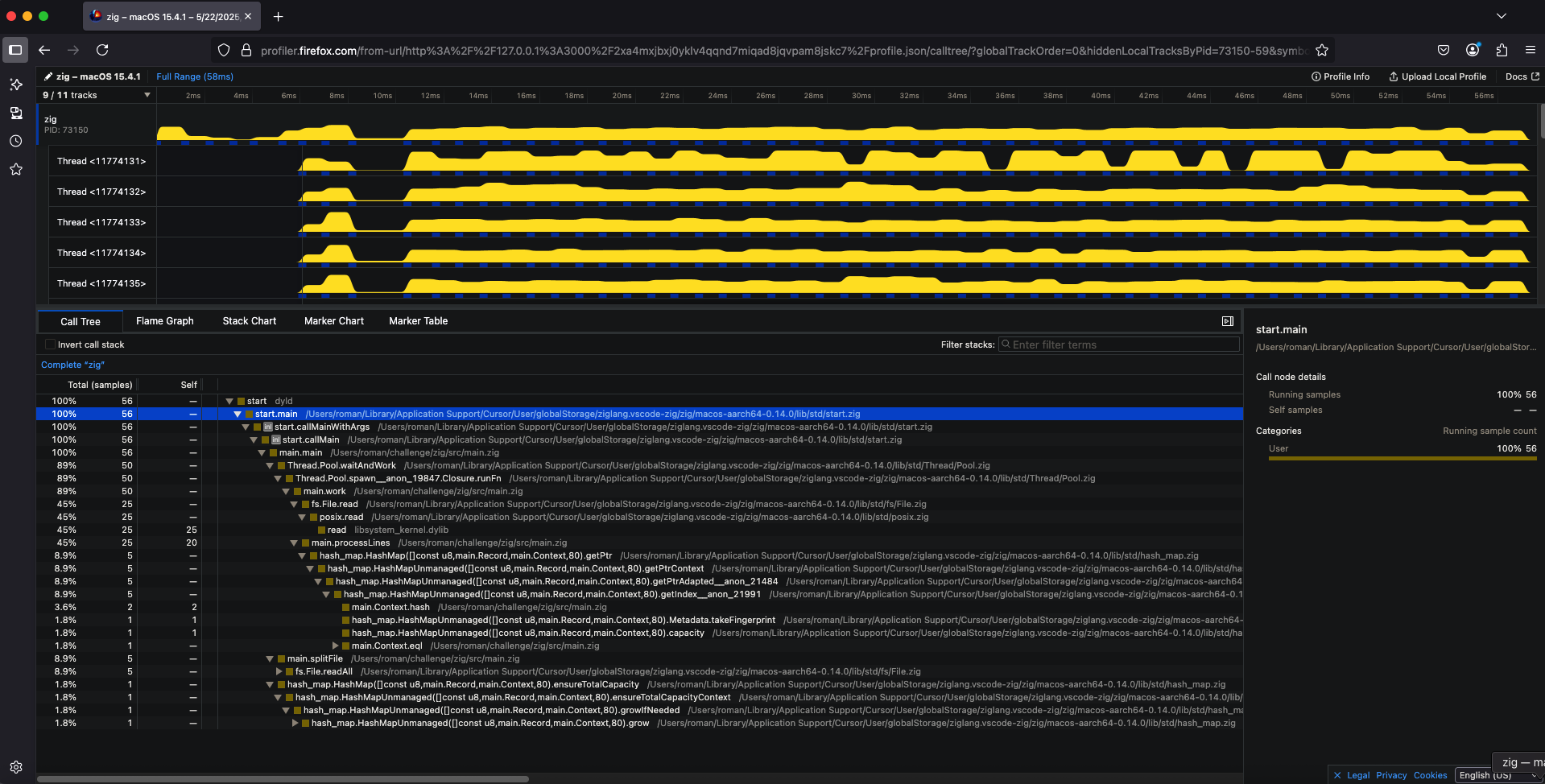
Как видно, результат аналогичен тому, что мы получили с помощью Time Profiler. Основное время программа тратит на чтение файла и обновление структуры данных типа HashMap, вероятно, во время записи промежуточных результатов.
Ещё один интересный способ профилирования — использование гибридного профилировщика Tracy (https://github.com/wolfpld/tracy). Его особенность в том, что вы самостоятельно размечаете участки кода с помощью специальных вызовов функций профилировщика.
В отличие от автоматических инструментов, интеграция с Tracy требует немного больше ручной работы. Зато вы получаете точный контроль над тем, какие именно участки кода будут профилироваться и когда. Это делает Tracy особенно полезным для тонкой настройки производительности.
Давайте начнем с разметки нашего кода, а потом посмотрим, как нам собрать нашу программу с поддержкой Tracy. Как я уже упоминал у нас есть программа, которая читает довольно крупный файл на диске (порядка 30Гб) и обрабатывает статистику из этого файла. Например наш файл содержит логи обработки запросов нашим сервисом в формате:
[TIMESTAMP] [IP_ADDRESS] [METHOD] [PATH] [STATUS_CODE] [RESPONSE_TIME_MS]
Полный код программы можно найти в репозитории. При обработке файла такого размера, выбор того или иного подхода на каждом этапе может значительно влиять на производительность. Например, мы можем выбрать между чтением файла построчно или используя буфферезированный ввод-вывод, а также между использованием одного потока или нескольких потоков, но с использованием механизмов синхронизации, таких как Mutex. Решения, выбранные на основании теоретических размышлений, не всегда дают ту производительность, на которую вы рассчитываете. Автор не раз натыкался на ситуации, что простые решения в лог нредко были не хуже, а иногда даже лучше сложных теоретических решений. Поэтому правильный подход все проверять на практике.
Так как профилировщик Tracy создавался для профилирования програм на C++, то для того чтобы использовать его для трассировки кода на zig, вам надо либо самим написать адаптер, либо использовать готовый. В нашем примере мы используем готовый адаптер, но в целом нет ничего сложного в том, чтобы написать свой. Для связки с Tracy мы используем библиотеку zig-tracy (https://github.com/johan0A/zig-tracy).
Для того чтобы провести профиллирование нашего кода мы добавим в наш код разметку, помечания интересующие блоки кода как отдельные зоны профилирования. В zig-tracy это делается с помощью специальных функций: можно использовать zone для автоматического именования зон по месту в исходном коде или zoneEx — для создания именованных зон, которые будут отображаться с заданным названием в интерфейсе профилировщика. Давайте рассмотрим пример кода:
fn processLines(lines: []const u8, threadMap: *Map, string_pool: *StringPool) void {
var spaceCount: u8 = 0;
var pathStart: usize = 0;
var pathEnd: usize = 0;
var timeStart: usize = 0;
// Создаем фрейм на всю функцию
const zone = tracy.zone(@src());
defer zone.end();
var i: usize = 0;
while (i < lines.len) : (i += 1) {
const c = lines[i];
if (c == ' ') {
spaceCount += 1;
switch (spaceCount) {
3 => pathStart = i + 1,
4 => pathEnd = i,
5 => timeStart = i + 1,
else => {},
}
continue;
}
if (c == '\n') {
// Создаем именнованный фрейм для обработки результатов
const process_results_zone = tracy.zoneEx(@src(), .{ .name = "Process results" });
const path = string_pool.intern(lines[pathStart..pathEnd]) catch {
std.debug.print("Failed to intern path: {s}\n", .{lines[pathStart..pathEnd]});
return;
};
const responseTime = std.fmt.parseInt(i32, lines[timeStart..i], 10) catch {
std.debug.print("Failed to parse response time: {s}\n", .{lines[timeStart..i]});
return;
};
if (threadMap.getPtr(path)) |record| {
record.update(responseTime);
} else {
if (Record.init(path, responseTime)) |record| {
threadMap.put(record.path, record) catch {
std.debug.print("Failed to put record into thread map\n", .{});
};
} else |_| {}
}
// Завершаем наш фрейм
process_results_zone.end();
spaceCount = 0;
}
}
}
В данном коде мы создаем два фрейма для профилировщика - один на всю функцию, которая обрабатывает строку, а второй раз на код, который парсит нужные данные из строки и обновляет статистику. Разметив таким образом наш код, мы сможем проще понимать результаты профилирования когда будем изучать их в UI профилировщика. Вот пример того, как это выглядит в UI профилировщика:
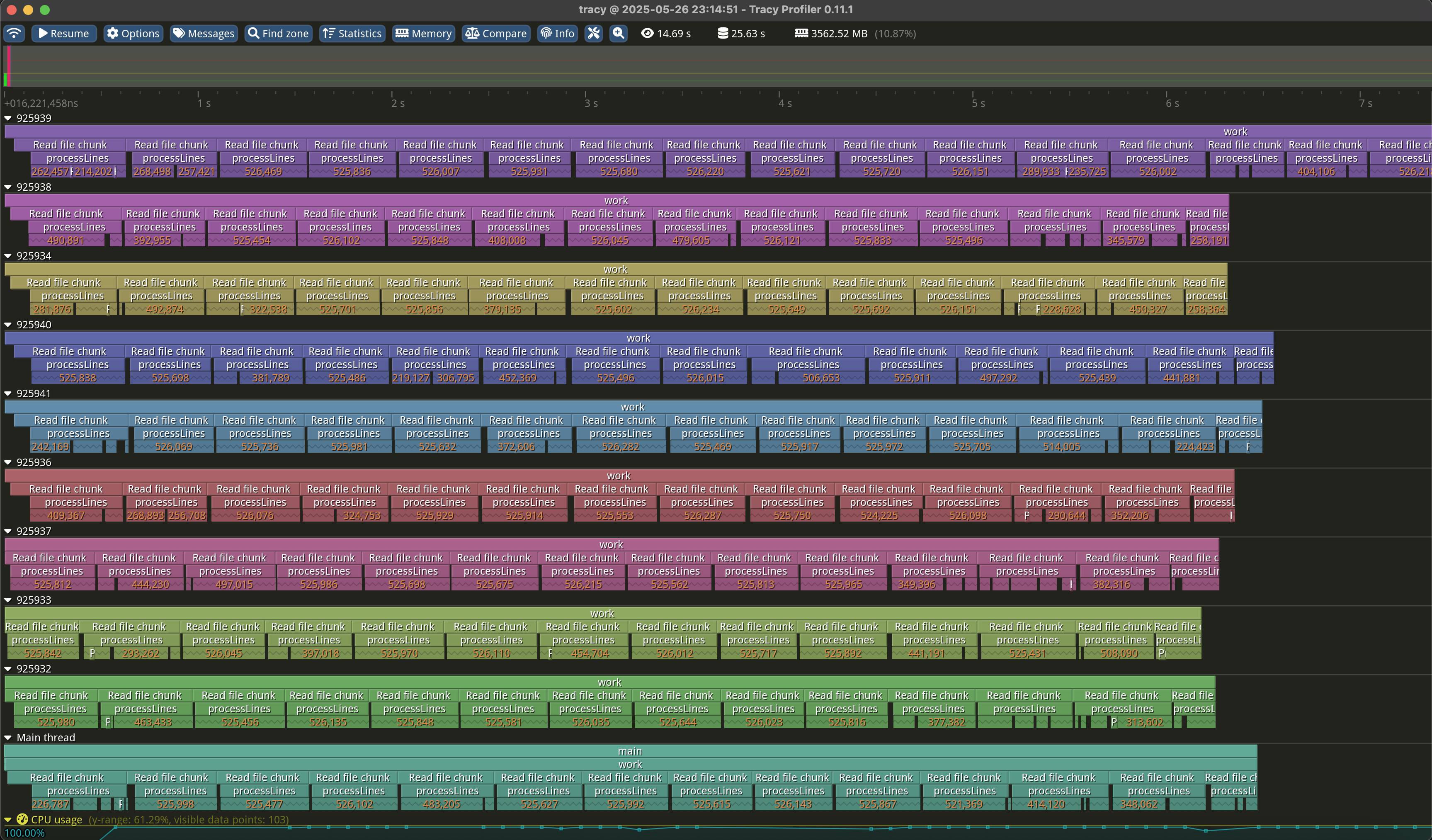
Кроме разметки кода для отслеждивания таймингов, пакет интеграции с zig-tracy позволяет использовать свой аллокатор, чтобы отслеживать память, используемую в процессе выполнения кода. А также вы можете логировать сообщения и строить графики производительности. В целом это довольно полезный инструмент, если вы хотите иметь возможность отслеживать производительность вашего кода и оптимизировать его.
Отладка кода
Если мы не можем отлаживать код, который пишем, то разрабатывать приложения на таком языке программирования становится очень трудным. Поэтому очень важно сразу убедится, что у Вас под рукой есть инструмент, который позволяет вам проводить отладку кода. Для того, чтобы отлаживать код на zig у нас есть несколько способов, но мы рассмотрим всего два - использование отладчика lldb и отладку кода в VS Code. Давайте начнем с использования отладчика lldb. Чтобы использовать отладчик Вам для начала необходимо его установить. Если у Вас Mac OS, то Вы можете установить его с помощью Homebrew:
brew install lldb
В остальных случаях вы можете установить его с помощью пакетного менеджера вашей операционной системы или скачать с официального сайта https://lldb.llvm.org/.
Прежде чем начать отладку вашей программы, её необходимо скомпилировать с поддержкой отладочной информации:
zig build
После того, как вы скомпилировали вашу программу для запуска отладки вам необходимо выполнить команду:
lldb ./zig-out/bin/your_program_name
В результате в консоли вы увидите следующее:
(lldb) target create "./zig-out/bin/your_program_name"
Current executable set to './zig-out/bin/your_program_name' (x86_64).
(lldb)
Самый простой способ начать отладку вашей программы это установить точку останова.
Для того чтобы установить точку останова вы можете либо использовать команду breakpoint set -l <номер строки>, либо установить точку останова на конкретную функцию с помощью команды breakpoint set -n <имя функции>. Установив точку останова, введите команду run для запуска отладки. Это запустит программу в режиме отладки. Исполнение автоматически приостановится на указанной вами точке останова. Рассмотрим пример: допустим, вы хотите установить точку останова на функцию splitFile. В этом случае используйте следующую команду:
(lldb) breakpoint set -n splitFile
Breakpoint 1: where = tracy`main.main + 2232 [inlined] root.zoneEx at root.zig:48:35, address = 0x0000000100018150
(lldb) run
Process 25838 launched: '/Users/roman/Projects/1brc/zig-out/bin/tracy' (arm64)
Process 25838 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100018150 tracy`main.main [inlined] root.zoneEx at root.zig:48:35 [opt]
45 const zone_context = if (options.callstack_support)
46 c.___tracy_emit_zone_begin_callstack(&global.loc, depth, 1)
47 else
-> 48 c.___tracy_emit_zone_begin(&global.loc, 1);
49
50 return Zone{ .zone_context = zone_context };
51 }
Target 0: (tracy) stopped.
warning: tracy was compiled with optimization - stepping may behave oddly; variables may not be available.
(lldb)
Если всё настроено правильно, LLDB остановит выполнение именно в момент входа в функцию splitFile. С этого момента вы сможете пошагово исследовать выполнение программы, просматривать значения переменных и управлять выполнением.
Чтобы пошагово проследить выполнение вашей программы в LLDB, используйте команды step (s) и next (n). Команда step выполняет текущую строку и заходит внутрь вызываемой функции, если таковая есть, а next выполняет строку целиком, переходя к следующей, не заходя внутрь функций. Это позволяет удобно анализировать поведение программы построчно.
Для того чтобы увидеть текущий стек вызовов, используйте команду bt (сокращение от backtrace). Она показывает, какие функции были вызваны вплоть до текущего момента, и помогает понять, в каком контексте находится выполнение.
Чтобы посмотреть значения локальных переменных в текущем фрейме (то есть в текущей функции), используйте команду frame variable (fr v). Можно также указать имя переменной, чтобы вывести только её значение.
Если нужно посмотреть содержимое массива или памяти, на которую указывает указатель (например, в случае []u8), можно воспользоваться командой memory read. Например, команда memory read --format x --count 10 --size 1 <ptr> выведет 10 байт по указанному адресу в шестнадцатеричном виде. Это полезно, если вы хотите вручную просмотреть данные, которые лежат в памяти в виде массива байтов.
Давайте теперь рассмотрим пример, как можно вывести на экран часть строки из памяти в рамках нашего приложения:
(lldb) breakpoint set -l 333
Breakpoint 2: where = tracy`Thread.Pool.spawn__anon_3093.Closure.runFn + 2012 [inlined] main.work + 1960 at main.zig:333:42, address = 0x00000001000174d4
(lldb) run
Process 29118 launched: '/Users/roman/Projects/1brc/zig-out/bin/tracy' (arm64)
Process 29118 stopped
* thread #5, stop reason = breakpoint 2.1
frame #0: 0x00000001000174d4 tracy`Thread.Pool.spawn__anon_3093.Closure.runFn [inlined] main.work(threadId=<unavailable>, offset=<unavailable>, partSize=3190541438, wait_group=0x000000016fdfdd80) at main.zig:333:42 [opt]
330 lineBuff.clearRetainingCapacity();
331 remainder.clearRetainingCapacity();
332 } else {
-> 333 processLines(buf[0 .. ln + 1], threadMap, &string_pool);
334 }
335
336 if (ln < n - 1) {
Target 0: (tracy) stopped.
warning: tracy was compiled with optimization - stepping may behave oddly; variables may not be available.
(lldb) fr v buf
([]u8) buf = (ptr = "2023-05-27T00:00:42.534Z 151.160.8.118 POST /api/metrics 400 14\n2023-05-27T00:00:42.465Z 191.147.98.180 PUT /api/health 500 119\n2023-05-27T00:00:42.587Z 130.168.101.82 GET /api/reviews 201 6\n2023-05-27T00:00:42.570Z 245.244.232.106 GET /api/docs 201 10\n2023-05-27T00:00:42.594Z 25.146.167.26 POST /api/checkout 200 14\n2023-05-27T00:00:42.861Z 36.236.245.201 GET /api/settings 200 216\n2023-05-27T00:00:42.685Z 178.1.79.126 PUT /api/login 200 33\n2023-05-27T00:00:42.879Z 188.39.181.87 GET /api/logout 200 92\n2023-05-27T00:00:42.978Z 182.236.178.54 GET /api/verify 200 90\n2023-05-27T00:00:42.830Z 25.80.133.87 GET /api/reviews 403 86\n2023-05-27T00:00:42.942Z 3.168.88.209 PUT /api/logout 204 114\n2023-05-27T00:00:43.081Z 134.215.254.62 GET /api/login 200 53\n2023-05-27T00:00:43.135Z 20.223.109.174 GET /api/settings 200 315\n2023-05-27T00:00:43.085Z 153.56.126.251 GET /api/orders 200 192\n2023-05-27T00:00:43.197Z 100.97.16.201 PUT /api/comments 200 162\n2023-05-27T00:00:43.192Z 155.239.27.61 PUT /api/settings 400 200\n2023-05-2"..., len = 33554432)
(lldb) memory read --format Y --count 30 --size 1 buf.ptr
0x107610000: 32 30 32 33 2d 30 35 2d 32 37 54 30 30 3a 30 30 2023-05-27T00:00
0x107610010: 3a 34 32 2e 35 33 34 5a 20 31 35 31 2e 31 :42.534Z 151.1
(lldb) memory read --format Y --count 30 --size 1 `buf.ptr+10`
0x10761000a: 54 30 30 3a 30 30 3a 34 32 2e 35 33 34 5a 20 31 T00:00:42.534Z 1
0x10761001a: 35 31 2e 31 36 30 2e 38 2e 31 31 38 20 50 51.160.8.118 P
(lldb)
В этом примере мы устанавливаем точку останова на строчку processLines(buf[0 .. ln + 1], threadMap, &string_pool); нашей программы, а когда мы там оказываемся мы используя команду memory read выводим часть содержимого нашего буфера с данными.
Для того чтобы код на zig в отладчике выглядел приятней и вы могли проще получать значения строковых переменных или массивов рекомендуется установить дополнение к lldb из поставки zig (https://github.com/ziglang/zig/blob/master/tools/lldb_pretty_printers.py). Процесс установки расширения расписан прямо в самом файле. После установки данного расширения просмотр []u8 срезов можно будет выполнять командой p lines. Я специально не стал сразу использовать данное расширение, чтобы показать вам как работать с кодом даже на “голом” отладчике.
Конечно использование консольного отладчика делает вас настоящими адептами отладки в консоли, но зачастую это не самый удобный способ отладки, особенно когда вы работаете с большими данными или когда вам нужно отслеживать состояние программы в реальном времени. Гораздо проще вести отладку в вашей IDE. Для того чтобы отлаживать код в VSCode вам необходимо поставить расширение CodeLLDB (https://github.com/vadimcn/codelldb). После установки расширения необходимо добавить два конфига и вы сможете отлаживать код в VSCode. В конфиг tasks.json настроек Vs Code нужно добавить следующее фрагмент:
{
"version": "2.0.0",
"tasks": [
{
"label": "zig build",
"type": "shell",
"command": "zig",
"args": ["build"],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}
А в конфиг launch.json нужно добавить следующее:
{
"version": "0.2.0",
"configurations": [
{
"type": "lldb",
"request": "launch",
"name": "Debug Main",
"program": "${workspaceFolder}/zig-out/bin/${workspaceFolderBasename}",
"preLaunchTask": "zig build",
"args": [],
"cwd": "${workspaceFolder}",
"console": "integratedTerminal"
}
]
}
После этого Вы сможете ставить точки останова в вашем коде и отлаживать ваше приложение в VSCode. Это конечно гораздо удобнее консольного отладчика и позволит вам быстро и эффективно находить и исправлять ошибки в вашем коде.
Заключение
В этой главе мы рассмотрели три важнейших аспекта разработки на языке Zig: форматирование, профилирование и отладку кода.
Форматирование кода в Zig — это не просто вопрос эстетики, а встроенная функциональность языка, обеспечивающая единообразие стиля во всех проектах. В отличие от многих других языков, где существуют споры о стилях форматирования, Zig предлагает единственное официальное решение, что упрощает совместную работу и повышает читаемость кода.
Профилирование позволяет выявить узкие места в производительности вашего приложения. Мы научились использовать инструменты для измерения времени выполнения различных функций и оптимизации наиболее ресурсоемких частей программы. Такой подход к оптимизации — “сначала измерь, потом улучшай” — позволяет сосредоточить усилия там, где они действительно нужны.
Отладка кода — неотъемлемая часть процесса разработки. Мы рассмотрели настройку среды VS Code для эффективной отладки Zig-программ, что позволяет быстро находить и исправлять ошибки в коде. Правильно настроенная отладка существенно сокращает время разработки и повышает качество конечного продукта.
Вместе эти три аспекта формируют надежный фундамент для разработки высококачественного, производительного и поддерживаемого кода на Zig. Освоив их, вы значительно повысите свою эффективность как Zig-разработчика и сможете создавать более надежные и оптимизированные программы.